RNN的實作適合用在有序列關係上的資料,因此我們利用python的twstock套件去做預測。twstock內包含臺灣的多種股票資訊,我們接下來的實作會選擇2021年的台塑股票進行預測分析。
首先先透過twstock將2021年的台塑股票資訊下載成一個csv檔,這邊要注意到我們在下載檔案時,一次最好以兩個月為限,如果一次下載太多的話有可能被鎖住IP,但真的被鎖住也不用擔心,過一段時間再回來執行就好。可以看見note1的地方,就是更改時間區間的範圍,只要將range內的數值做修改,就可以換成對應的月份。note2指的是股票代號,若是不想做台塑的有可以換成別間股票,在Yahoo!奇摩股市(https://tw.stock.yahoo.com/h/kimosel.php) 可以搜尋到各種台股的編號。最後要注意在第一次執行這段程式時,在note3的第二個參數使用"w",之後則使用"a","w"代表寫入模式,他會寫一個新的檔案,若是檔案已存在則會覆蓋原有檔案,這也是為什麼後面要改用"a"模式。"a"模式是附加模式,他會將新的資料接在原有的資料後,這樣原本的檔案就不會被覆蓋囉!
import csv
import twstock
import os
filepath = "stock2021.csv"
data = []
for i in range(1, 3): # note1
stock = twstock.Stock("1301") # note2
stocklist = stock.fetch(2021, i)
for stock in stocklist:
strdate = stock.date.strftime("%Y-%m-%d")
li = [strdate, stock.capacity, stock.turnover, stock.open, stock.high, stock.low, stock.close, stock.change, stock.transaction]
data.append(li)
outputfile = open(filepath, "w", newline = "", encoding = "big5") # note3
outputwriter = csv.writer(outputfile)
for dataline in (data):
outputwriter.writerow(dataline)
outputfile.close()
在獲得股票資訊的csv檔過後,我們就可以開始著手準備訓練模型了!首先我們定義一個切分訓練及以及測試集的函式,函式的參數feature_data代表特徵的資料、label_data代表標籤的資料、length為訓練長度,也就是要以多長的feature去預測下一個label、split代表訓練集對於測試集的比例。
def load_data(feature_data, label_data, length, split):
feature_all = np.array(feature_data).astype(float)
feature_all = scaler.fit_transform(feature_all)
label_all = np.array(label_data).astype(float)
label_all = scalert.fit_transform(label_all)
feature = []
label = []
for i in range(len(feature_all) - length):
feature.append(feature_all[i: i + length])
label.append(label_all[i + length])
x = np.array(feature).astype("float64")
y = np.array(label).astype("float64")
split_boundary = int(x.shape[0] * split)
train_x = x[: split_boundary]
test_x = x[split_boundary: ]
train_y = y[: split_boundary]
test_y = y[split_boundary: ]
return train_x, train_y, test_x, test_y
下一步要來建構RNN模型,我們直接引入keras.layer中的SimpleRNN做模型的建構。
def build_model():
model = Sequential()
model.add(SimpleRNN(input_shape = (10, 3), units = 256, unroll = False))
model.add(Dense(units = 1))
model.compile(loss = "mse", optimizer = "adam", metrics = ["accuracy"])
return model
建構完模型後,接著就要來做最重要的一步,那就是訓練模型啦!訓練模型的部分,筆者採用300個epochs以及10%的驗證集比例去做訓練,讀者可以嘗試去調整看看,說不定會得到更好的結果喔!
def train_model(train_x, train_y, test_x, test_y):
model.fit(train_x, train_y, batch_size = 100, epochs = 300, validation_split = 0.1)
predict = model.predict(test_x)
predict = np.reshape(predict, (predict.size, ))
return predict
在將我們所需要的功能都寫成函式過後,接下來就只要一一呼叫他們就可以完成模型的訓練了。首先是讀取股票資料的csv檔,再來是區分訓練集以及測試集、建立模型、訓練模型。
filename = "stock2021.csv"
df = pd.read_csv(filename, encoding = "big5")
ddtrain = df[["收盤價", "最高價", "最低價"]]
ddprice = df[["收盤價"]]
scaler = MinMaxScaler()
scalert = MinMaxScaler()
train_x, train_y, test_x, test_y = load_data(ddtrain, ddprice, 10, 0.8)
model = build_model()
predict_y = train_model(train_x, train_y, test_x, test_y)
predict_y = scalert.inverse_transform([[i] for i in predict_y])
test_y = scalert.inverse_transform(test_y)
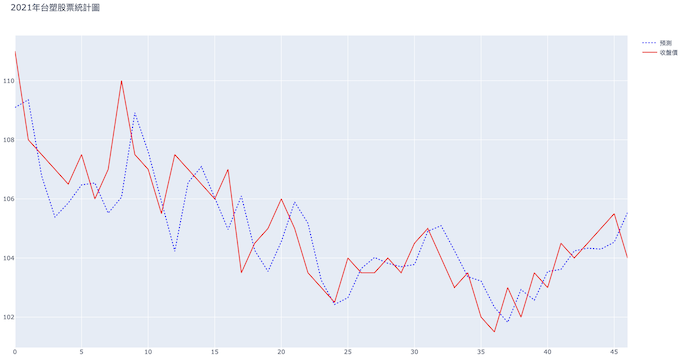
最後我們利用python的plotly來繪製結果圖。先將預測結果以及實際結果放進dataframe中,再將dataframe以散佈圖的方式丟進plotly的函式,就可以得到一個圖表的html檔了!
result = pd.DataFrame({"predict": list(predict_y), "label": list(test_y)})
result["predict"] = np.array(result["predict"]).astype("float64")
result["label"] = np.array(result["label"]).astype("float64")
data = [
Scatter(y = result["predict"], name = "預測", line = dict(color = "blue", dash = "dot")),
Scatter(y = result["label"], name = "收盤價", line = dict(color = "red"))
]
plot({"data": data, "layout": Layout(title = "2021年台塑股票統計圖")}, auto_open = True)
最終繪製出來的結果如下,從圖表上來看好像挺精確的,但其實真正的股票預測比這個還要來得難上許多,而且一點的誤差可能都會導致損失嚴重,因此如果想利用這個來賺股票發財的話,可能要多加考慮喔。